Reviewers are also interested in the "who," and for that -- at least in part -- we have social network analysis. In our increasingly connected world, it is more and more interesting and valuable -- and possible -- to explore and understand those connections and relationships. Recently of note, LinkedIn has started offering that capability. And NodeXL, which we'll be looking at here, does that for several other social networking platforms.
For this project, the questions I'm working to help answer are: Who is talking about this topic? Who should we depose? Whose documents should we request/subpoena? And the clues are coming not from email systems or the Web (today, anyway) but from a set of documents that have been discovered, reviewed and produced to us in TIF/Text format.
Given native docs, or crawling your own network, there are more options open for metadata analysis of "who." Clearwell offers some aspects of social network analysis, and I have heard that Humanizing Technologes will soon launch an eDiscovery tool that may do this. And for the Enron data in particular there's Enronic. However, we're often limited to at best a few fields that give sender and recipient information. And that's where today's post begins.
Just as before, I collected documents based on their content, and exported them to delimited text files. For this exercise, though, I exported only the from, to, cc and bcc fields. For example:

- Extract from the output all email addresses
- Make a deduplicated list of email addresses
- For each pair of addresses, count the number of messages they shared, as sender-recipient or recipient-recipient
- Create text output listing each pair that shared at least one message, and the number of messages they shared
Here's a screenshot of a NodeXL woorkup on the Regulation documents.
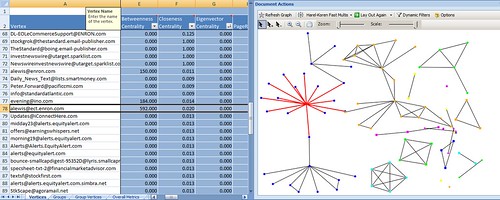
This is an analysis of 238 emails that contained the word "regulation." We see several unconnected groups, and I highlighted a central node in one of them. When a node is selected on the graph, NodeXL automatically highlights its corresponding entry in the vertices table. There we see that address belonged to Andrew Lewis, who is identified on this list of former Enron employees as a "Director." That makes him a likely target for deposition or document request, and, as an executive, one that would be identified early in the case.
A less likely target, though, would be Mark Whitt, who is identified on the employee list as "N/A". Yet there he is, linking to two branches of a large group that includes executives like VP Barry Tycholiz.
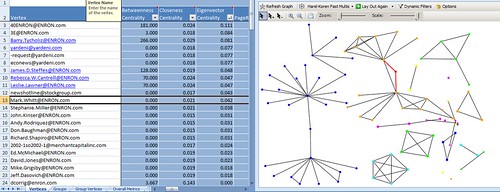
Now, in Concordance (or Summation, etc., whatever review tool we're using) our next query can be something like "(AUTHOR CO Whitt) OR (TO CO Whitt) OR (CC CO Whitt) OR (BCC CO Whitt)" as a way to shape review. In fact, we can sort our network based on the most connected nodes and start from there.
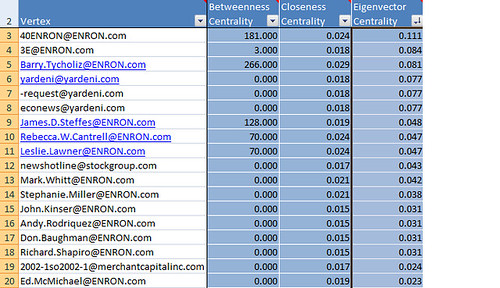
So, a few things we can do here: If a person has high connectivity on a topic, i.e., s/he is talking a lot to the rest of the corpus about it, then they may make a good deponent. If we did not receive their documents/emails, despite our request for all responsive, this may be a problem. If a high-ranker is not listed in the initial important-persons list, we may want to request their documents. If a high-ranker is not a person, but a service, for example, we may want to ask our deponents about this service. All this, coupled with semantic network analysis, may provide a useful review scheme. And I will work on that...
Speaking of working on it, I know my discovery email scraper has shortcomings. It is an alpha version. The beta version will hopefully:
- distinguish between sender and recipient, to provide directional ties between nodes,
- associate names and email addresses, to make use of fields that list a sender or recipient by name only, and
- export to GraphML, to save the the copying-and-pasting into NodeXL.
No comments:
Post a Comment