Reader Paul C. Easton made the excellent suggestion that I zip up and share the test data being used in this experiment. And I agree for at least three (related) reasons: I too would like to see how other tools would handle this data set; I currently have no access to LAW, and would love to hear from someone who does; and as interesting as this project already is, it can only improve on input from others. So here goes (59.2 MB - be patient).
Please let me know how you make out with this, and thanks, Paul! I will be sharing my FreeEed results ASAP.
Note - inside the zip archive, there is a RENAME_LOG that lists the files whose extensions I intentionally switched. That file itself was not processed in the test runs.
Tuesday, March 27, 2012
Thursday, March 15, 2012
eDiscovery - Lower in the Stack pt.II - Concordance
This is part 2 of a project I started to look at some data-gathering tools, absent LAW and Clearwell, which I had been using since this blog's outset.
Concordance is best known -- and probably best used -- as a review tool. However, it does have the ability to discover and import edocs, email and transcripts, in addition to the industry standard "Concordance style" TIF/TXT loads of the same.
I have on occasion used Concordance to add edocs to existing document collections in cases. Most often, it works fine for PDFs, with two caveats: Adobe Reader or Acrobat must be installed on the same machine, and any document text needs to be already extracted, as Concordance has no OCR engine. This, coupled with the fact that Acrobat by default will not OCR a doc with any text in it can leave you with PDFs that show up like this:
[ASDF-000123]
[ASDF-000124]
[ASDF-000125]
[ASDF-000126]
Actually, Concordance has no on-board document processing tools at all, but uses other installed programs to extract metadata natively. Most of the time, including now, this means MS Office and Acrobat.
Here's the basic procedure:
After creating a blank eDocs database, select Import > Edocs from the menu, and select your population by location and doc type:
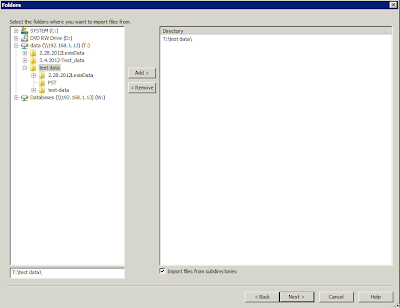

You decide how to match gathered metadata to your database fields, and start the import. Logging is less-than-verbose.
 But at least you have a list of the error docs for your QC. Here's a shot of the Concordance screen looking at a PDF after import:
But at least you have a list of the error docs for your QC. Here's a shot of the Concordance screen looking at a PDF after import:

The auto-hyperlinking is convenient. Those hyperlinks will launch a doc's native viewer, and works as long as the data location will not change. However, Concordance ships with a pile of scripts, one of which can adjust the link fairly easily.
Here is the list of metadata Concordance pulls:
It will do its best to populate those fields with what it finds in the docs.
Results
I imported files using the *.* method, where any object in the specified path is processed. For reference, here's a rundown on the source data:
And here is an export from the database of all file extensions.
Emails are processed with a different database module. At least the email files were included in the error log, so the admin knows they're not in the database. There are two reasons the count increased on import:
1. This import method takes every object in the supplied path, including system files like Thumbs.db and *.store_ds, so there's obviously no NIST culling with Concordance.
2. Concordance handles multi-sheet excel files by splitting each sheet into a separate document, much to the chagrin of reviewers; the hyperlinks on the docs pulled from a 14-sheet excel file will point to that file 14 times.
Another "Easter Egg" in this dataset are the bogus extensions I set before copying up to the server. I took a handful of files and, like a user sometimes will, gave them incorrect extensions. For example, here's a bit of text from a PDF I renamed to *.xls:
So furthermore there is no MIME type discovery prior to processing. And given that some text was able to be extracted, there was no error for Concordance to report. This document, let's say it's being reviewed in response to a copyright violation complaint, has been rendered unresponsive. As scale increases, so does the risk involving issues like these.
In part 3 I will share the results of using FreeEed to process this same dataset. I very much welcome your input. Thank you for reading.
Concordance is best known -- and probably best used -- as a review tool. However, it does have the ability to discover and import edocs, email and transcripts, in addition to the industry standard "Concordance style" TIF/TXT loads of the same.
I have on occasion used Concordance to add edocs to existing document collections in cases. Most often, it works fine for PDFs, with two caveats: Adobe Reader or Acrobat must be installed on the same machine, and any document text needs to be already extracted, as Concordance has no OCR engine. This, coupled with the fact that Acrobat by default will not OCR a doc with any text in it can leave you with PDFs that show up like this:
[ASDF-000123]
[ASDF-000124]
[ASDF-000125]
[ASDF-000126]
"Yes, I Batch-OCRed everything before importing it. Right after I added the Bates footers."
Actually, Concordance has no on-board document processing tools at all, but uses other installed programs to extract metadata natively. Most of the time, including now, this means MS Office and Acrobat.
Here's the basic procedure:
After creating a blank eDocs database, select Import > Edocs from the menu, and select your population by location and doc type:


You decide how to match gathered metadata to your database fields, and start the import. Logging is less-than-verbose.


The auto-hyperlinking is convenient. Those hyperlinks will launch a doc's native viewer, and works as long as the data location will not change. However, Concordance ships with a pile of scripts, one of which can adjust the link fairly easily.
Here is the list of metadata Concordance pulls:
TITLE
SUBJECT
AUTHOR
COMPANY
CATEGORY
KEYWORDS
PRODUCER
CREATOR
COMMENTS
METADATA
FILEPATH
DATE
MODDATE
CREATIONDATE
PRINTDATE
TEXT01
TEXT02
TEXT03
TEXT04
TEXT05
It will do its best to populate those fields with what it finds in the docs.
Results
I imported files using the *.* method, where any object in the specified path is processed. For reference, here's a rundown on the source data:
Files: 208
Extensions:
doc 41
pdf 73
xls 19
xlsx 1
htm 4
html 18
eml 4
txt 8
csv 1
pst 3
ppt 12
[none] 3
1b 1
exe 1
db 1
zip 5
jpg 6
odp 1
odt 1
docx 1
pps 1
wav 1
msg 2
And here is an export from the database of all file extensions.
Files: 253
Extensions:
csv,1
db,1
doc,41
docx,1
exe,1
htm,4
html,14
jpg,6
msg,2
odp,1
odt,1
pdf,73
pps,1
ppt,11
pst,3
txt,8
wav,1
xls,73
xlsx,3
zip,5
db,1
doc,41
docx,1
exe,1
htm,4
html,14
jpg,6
msg,2
odp,1
odt,1
pdf,73
pps,1
ppt,11
pst,3
txt,8
wav,1
xls,73
xlsx,3
zip,5
1b,1
[blank],1
[blank],1
Emails are processed with a different database module. At least the email files were included in the error log, so the admin knows they're not in the database. There are two reasons the count increased on import:
1. This import method takes every object in the supplied path, including system files like Thumbs.db and *.store_ds, so there's obviously no NIST culling with Concordance.
2. Concordance handles multi-sheet excel files by splitting each sheet into a separate document, much to the chagrin of reviewers; the hyperlinks on the docs pulled from a 14-sheet excel file will point to that file 14 times.
Another "Easter Egg" in this dataset are the bogus extensions I set before copying up to the server. I took a handful of files and, like a user sometimes will, gave them incorrect extensions. For example, here's a bit of text from a PDF I renamed to *.xls:
%PDF-1.2
%âãÏÓ
663 0 obj
<<
/Linearized 1
/O 668
/H [ 3860 1307 ]
/L 718869
/E 36196
/N 58
/T 705490
>>
endobj
%âãÏÓ
663 0 obj
<<
/Linearized 1
/O 668
/H [ 3860 1307 ]
/L 718869
/E 36196
/N 58
/T 705490
>>
endobj
And here is part of what this document actually says:
Microsoft® Windows® and the Windows logo are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Netscape® and Netscape Navigator are registered trademarks of Netscape Communications Corporation in the United States and other countries. The Netscape logo and the Netscape product and service names are also trademarks of Netscape Communications Corporation in the United States and other countries.
Netscape® and Netscape Navigator are registered trademarks of Netscape Communications Corporation in the United States and other countries. The Netscape logo and the Netscape product and service names are also trademarks of Netscape Communications Corporation in the United States and other countries.
So furthermore there is no MIME type discovery prior to processing. And given that some text was able to be extracted, there was no error for Concordance to report. This document, let's say it's being reviewed in response to a copyright violation complaint, has been rendered unresponsive. As scale increases, so does the risk involving issues like these.
In part 3 I will share the results of using FreeEed to process this same dataset. I very much welcome your input. Thank you for reading.
Monday, March 5, 2012
eDiscovery - Lower in the Stack
A recent career upgrade, however welcome, nevertheless cut off my access to LAW Prediscovery and Clearwell platforms for play and experimentation. This presented both the obligation and opportunity to explore other avenues and issues to which I might not have otherwise been introduced. Specifically, I had to get lower in the eDiscovery stack.
A stable, flexible domain with ample storage and powerful workstations was no more my personal playground. Step one was to build a replacement.

* It's important to note that FreeEed, designed as it is to run on a Hadoop cluster, should be able to scale way way WAY beyond the scope of my experiments. Here's hoping I get to the point soon to test those abilities. For now, I'll focus on usability and reliability.
A stable, flexible domain with ample storage and powerful workstations was no more my personal playground. Step one was to build a replacement.

Close enough?
It's neater up there now, but I thought this photo funny enough to share. Here's the current rundown on the CapitalToomey Data Center: Atop my family's WiFi, in the attic, I've got a Windows Server 2003 box running Concordance 9.58 and Free-EED 3.5. There's also an Acer Veriton M420 with Free-NAS that's been put through Proof-Of-Concept, but not yet filled with permanent drives (perhaps more on this later). So my small bit of case data is being housed on its own drive in the one work server. But it all works, so I'm happy with that at least. (As a quick side note, I've been using Microsoft's RDP Client for Mac, and it's been great.)
So, having reestablished a "work"environment, my question was one facing thousands of companies, law firms, consultants and litigants, everywhere, right now: How do we balance cost, effectiveness and reliability in handling this data?
eDiscovery for Small-to-Medium Data
If you have potentially relevant discoverable data that's too big to fit on a CD-R, you're probably in need of technological assistance in collecting and reviewing it. In the coming series of posts, I will review two potential solutions for eDiscovery on this scale: Concordance and FreeEed*. I will use them both to process a fairly standard batch of e-docs and emails, comparing the processes and results, and offering some observations from my own experience along the way.
The Data
The initial dataset for this project is what LexisNexis provided for Concordance certification training in 2007, a bit of the Enron emails and the FreeEed test data. It totals about 98 MB.
One very important aspect of any eDiscovery project that we will not be looking at here, however, is collection. Pulling data from your stores in a thorough and dependable way, without trampling the metadata and potentially invalidating its production...this is a field of expertise and many series of experiments in and of itself.
So, once it was "collected," I used RoboCopy to place the data on to the work server. Here is part of the nice log it creates:
And here is a report of the distribution of file extensions in this set.
These two logs are important, and will be used to validate our processing results.
And now we're ready to start consuming this stuff. I have made the first runs, and will start putting together the results to share.
Thank you for reading. Please check back soon. I will post updates to my twitter feed.
eDiscovery for Small-to-Medium Data
If you have potentially relevant discoverable data that's too big to fit on a CD-R, you're probably in need of technological assistance in collecting and reviewing it. In the coming series of posts, I will review two potential solutions for eDiscovery on this scale: Concordance and FreeEed*. I will use them both to process a fairly standard batch of e-docs and emails, comparing the processes and results, and offering some observations from my own experience along the way.
The Data
The initial dataset for this project is what LexisNexis provided for Concordance certification training in 2007, a bit of the Enron emails and the FreeEed test data. It totals about 98 MB.
One very important aspect of any eDiscovery project that we will not be looking at here, however, is collection. Pulling data from your stores in a thorough and dependable way, without trampling the metadata and potentially invalidating its production...this is a field of expertise and many series of experiments in and of itself.
So, once it was "collected," I used RoboCopy to place the data on to the work server. Here is part of the nice log it creates:
------------------------------------------------------------------------------
Total Copied Skipped Mismatch FAILED Extras
Dirs : 18 18 0 0 0 0
Files : 208 208 0 0 0 0
Bytes : 97.93 m 97.93 m 0 0 0 0
Times : 0:00:12 0:00:12 0:00:00 0:00:00
Speed : 8014316 Bytes/sec.
Speed : 458.582 MegaBytes/min.
Ended : Sun Mar 04 21:01:15 2012
Total Copied Skipped Mismatch FAILED Extras
Dirs : 18 18 0 0 0 0
Files : 208 208 0 0 0 0
Bytes : 97.93 m 97.93 m 0 0 0 0
Times : 0:00:12 0:00:12 0:00:00 0:00:00
Speed : 8014316 Bytes/sec.
Speed : 458.582 MegaBytes/min.
Ended : Sun Mar 04 21:01:15 2012
And here is a report of the distribution of file extensions in this set.
doc 41
pdf 73
xls 19
xlsx 1
htm 4
html 18
eml 4
txt 8
csv 1
pst 3
ppt 12
[none] 3
1b 1
exe 1
db 1
zip 5
jpg 6
odp 1
odt 1
docx 1
pps 1
wav 1
msg 2
These two logs are important, and will be used to validate our processing results.
And now we're ready to start consuming this stuff. I have made the first runs, and will start putting together the results to share.
Thank you for reading. Please check back soon. I will post updates to my twitter feed.
* It's important to note that FreeEed, designed as it is to run on a Hadoop cluster, should be able to scale way way WAY beyond the scope of my experiments. Here's hoping I get to the point soon to test those abilities. For now, I'll focus on usability and reliability.
Subscribe to:
Posts (Atom)