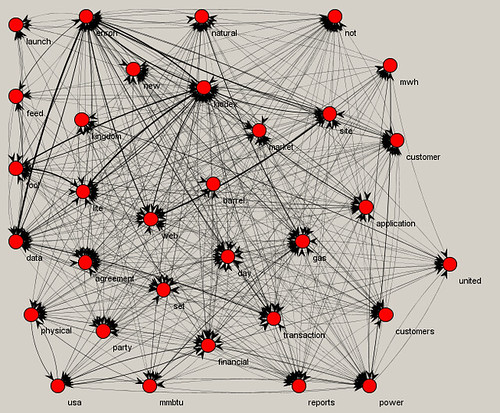
In
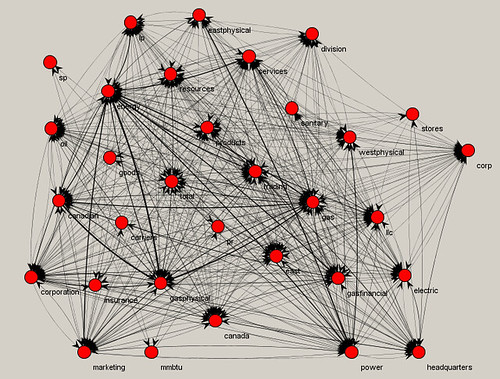
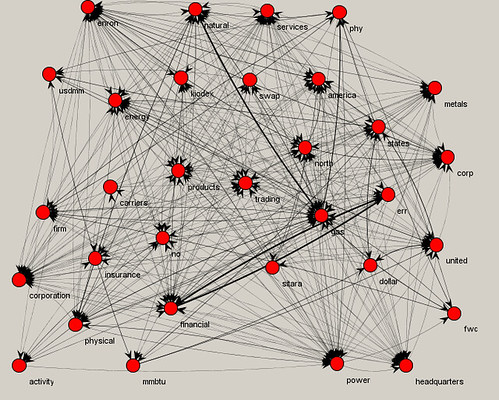
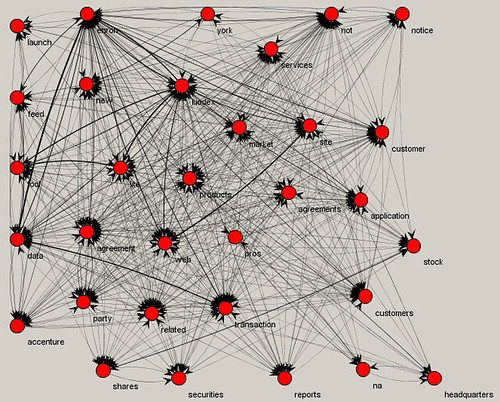
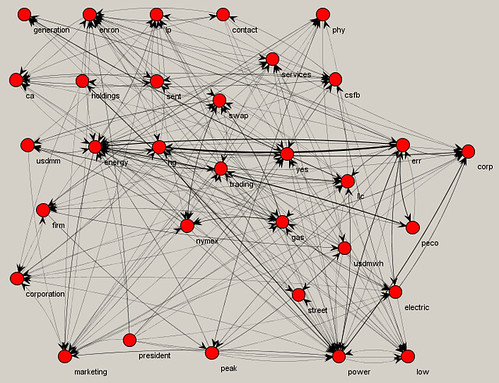
Part 1, I gave an overview of the general word use in subsets of the Enron corpus based on keywords. So, for example, we saw what words often occurred together in documents that also contained the word "profit." The idea here is to provide a clue into the responsiveness of a set of docs and the direction to take in search and review.
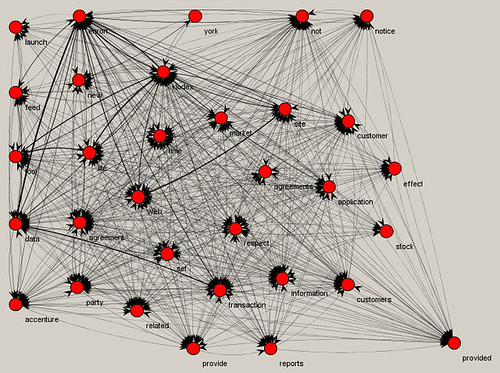
Going further, we can also create text strings based on a target start and end word, and what words often co-occurred in between. In the below examples, the target end word was the most central in each subset, i.e., it co-occurred with the most others.
Profit
profit -> loss -> or
profit -> reports -> kiodex -> or
profit -> reports -> kiodex -> enron -> or
profit -> reports -> enron -> or
profit -> reports -> kiodex -> will -> or
profit -> reports -> kiodex -> shall -> or
profit -> reports -> kiodex -> tool -> or
profit -> reports -> kiodex -> site -> or
profit -> reports -> enron -> kiodex -> or
profit -> reports -> kiodex -> in -> or
profit -> reports -> enron -> data -> or
profit -> reports -> kiodex -> web -> or
profit -> reports -> enron -> in -> or
profit -> reports -> kiodex -> lite -> or
profit -> reports -> kiodex -> such -> or
profit -> reports -> enron -> shall -> or
Here we see that the Kiodex tool from our general network graph for the "profit" docs is also associated, through the word "reports," with Enron's discussion of profit. There, without having actually looked at the documents, we have learned with a certain degree of certainty one of the uses of the Kiodex tool.
Offshore
offshore -> inc
offshore -> exploration -> inc
offshore -> exploration -> us -> energy -> inc
offshore -> exploration -> us -> gasphysical -> inc
offshore -> exploration -> us -> gas -> inc
offshore -> exploration -> us -> gasfinancial -> inc
offshore -> exploration -> us -> inc
offshore -> exploration -> company -> gasphysical -> inc
offshore -> exploration -> us -> resources -> inc
offshore -> exploration -> company -> gas -> inc
offshore -> exploration -> company -> us -> inc
offshore -> exploration -> company -> inc
offshore -> exploration -> company -> gasfinancial -> inc
offshore -> exploration -> us -> marketing -> inc
offshore -> exploration -> us -> power -> inc
offshore -> exploration -> gasphysical -> energy -> inc
A lot of talk here about gas and offshore exploration.
Corporate
corporate -> action -> or -> gas
corporate -> action -> or -> us -> gas
corporate -> action -> or -> company -> gas
corporate -> action -> or -> can -> gas
corporate -> power -> us -> gas
corporate -> power -> us -> natural -> gas
corporate -> power -> physical -> gas
corporate -> power -> physical -> us -> gas
corporate -> power -> physical -> natural -> gas
corporate -> power -> us -> physical -> gas
corporate -> power -> us -> financial -> gas
corporate -> power -> fwd -> us -> gas
corporate -> power -> firm -> us -> gas
corporate -> power -> us -> fin -> gas
corporate -> power -> fwd -> or -> gas
corporate -> power -> phy -> firm -> gas
Corporate action and power! That's what I like to hear a company talking about. I think I'll invest in them...
Regulation
regulation -> or
regulation -> under -> agreement -> or
regulation -> order -> or
regulation -> under -> or
regulation -> under -> agreement -> in -> or
regulation -> under -> agreement -> shall -> or
regulation -> under -> agreement -> enron -> or
regulation -> under -> agreement -> such -> or
regulation -> under -> securities -> or
regulation -> under -> such -> or
regulation -> under -> section -> or
regulation -> under -> agreement -> party -> or
regulation -> under -> agreement -> kiodex -> or
regulation -> under -> agreement -> may -> or
regulation -> under -> such -> in -> or
regulation -> under -> securities -> such -> or
Kiodex again, with regulation. We can't always tell which meaning of regulation is in use. Nevertheless, as head of a review team, I'd be assigning the Kiodex topic now.
Natural Gas
gas -> in -> or
gas -> mmbtu -> oil -> products -> or
gas -> mmbtu -> products -> or
gas -> in -> kiodex -> or
gas -> in -> such -> or
gas -> in -> enron -> or
gas -> in -> kiodex -> enron -> or
gas -> in -> agreement -> or
gas -> financial -> united -> products -> or
gas -> in -> enron -> kiodex -> or
gas -> financial -> usa -> products -> or
gas -> financial -> or
gas -> physical -> usa -> products -> or
gas -> mmbtu -> products -> kiodex -> or
gas -> mmbtu -> usa -> products -> or
gas -> in -> kiodex -> tool -> or
Electric
electric -> company -> in
electric -> company -> interested -> in
electric -> company -> ca -> in
electric -> power -> in
electric -> company -> enron -> set -> in
electric -> company -> enron -> data -> in
electric -> company -> contact -> in
electric -> power -> from -> in
electric -> company -> enron -> contact -> in
electric -> company -> sent -> ca -> in
electric -> power -> company -> in
electric -> company -> energy -> in
electric -> company -> person -> contact -> in
electric -> power -> enron -> set -> in
electric -> company -> enron -> ca -> in
electric -> power -> enron -> data -> in
Again, this would all be given to the review team before any documents are looked at, or any time is invested, and in that by itself the process has value. I am working to improve the other measures of its value. It would very much help to know more about this case so that I can know whether I'm right in calling a document hot or a search path relevant. So if you know where I can find more of that kind of information on these documents, please share.
There are several services and solutions offering this kind of analysis (examples:
TextAlalyst,
DiscoverText, and of course
Clearwell's "topics"). But this is stuff I thought of around the time I was introduced to Clearwell v3, and I'm now getting around to blogging about it, so I'm taking the long way around here, too - via my educational history. Who knows, the Social Network Analysis sections to come may skip
NodeXL and go back to the source:
UCINET.